C 语言数据在内存中的存储基本原理
我们都知道,C语言是一门面向过程的、抽象化的通用程序设计语言,广泛应用于底层开发。C语言能以简易的方式编译、处理低级存储器。同是正是因为 C 语言可以使用指针,从而对物理内存地址进行直接操作,这是 C 的最大特点之一。要理解好 C 语言,也需要对数据在内存中存储方式有基本的认识,本文以 C 为例子,介绍数据在内存中存储的基本原理。
内存空间与地址
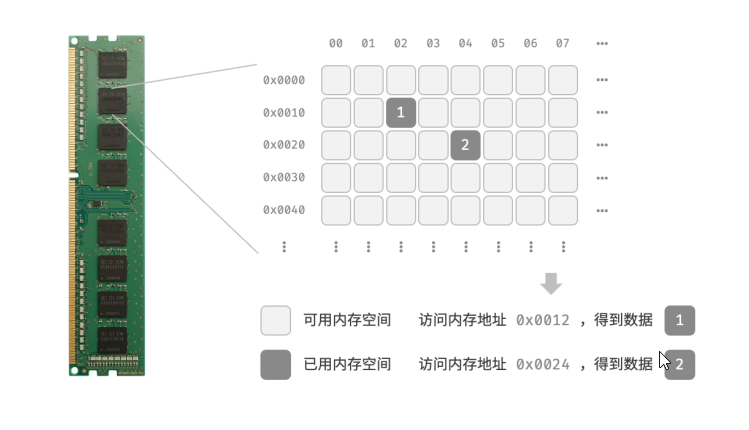
下图展示了一个计算机内存条,其中每个黑色方块都包含一块内存空间。我们可以将内存想象成一个巨大的 Excel 表格,其中每个单元格都可以存储一定大小的数据。系统通过内存地址来访问目标位置的数据。计算机根据特定规则为表格中的每个单元格分配编号,确保每个内存空间都有唯一的内存地址。有了这些地址,程序便可以访问内存中的数据。
最重要的概念:基本数据类型以二进制的形式存储在计算机中。一个二进制位即为 1 比特。在绝大多数现代操作系统中,1字节(byte)由 8 比特(bit)组成。
1. 数据类型
1.1 类型的基本归类
当谈及计算机中的数据时,我们会想到文本、图片、视频、语音、3D 模型等各种形式。尽管这些数据的组织形式各异,但它们都由各种基本数据类型构成。
C语言中有多种基本数据类型,包括整数、浮点数、字符等。这些数据类型在内存中占用的空间大小不同,例如,int通常占用4个字节,float占用4个字节,char占用1个字节。数据类型决定了数据在内存中的存储方式和表示形式,可以分为以下的五大类型:
1.1.1 整型
1 | |
1.1.2 浮点型
1 | |
1.1.3 构造类型
1 | |
1.1.4 指针类型
1 | |
1.1.5 空类型
1 | |
2. 整形在内存中的存储
C 变量的创建是根据数据类型在内存中开辟空间。
2.1 原码、反码、补码
数据在内存中以 2 进制的形式存储,以整数举例,其 2 进制存储有三种表示形式。
正整数:原码、反码、补码相同。
负整数:原码、反码、补码要进行计算。
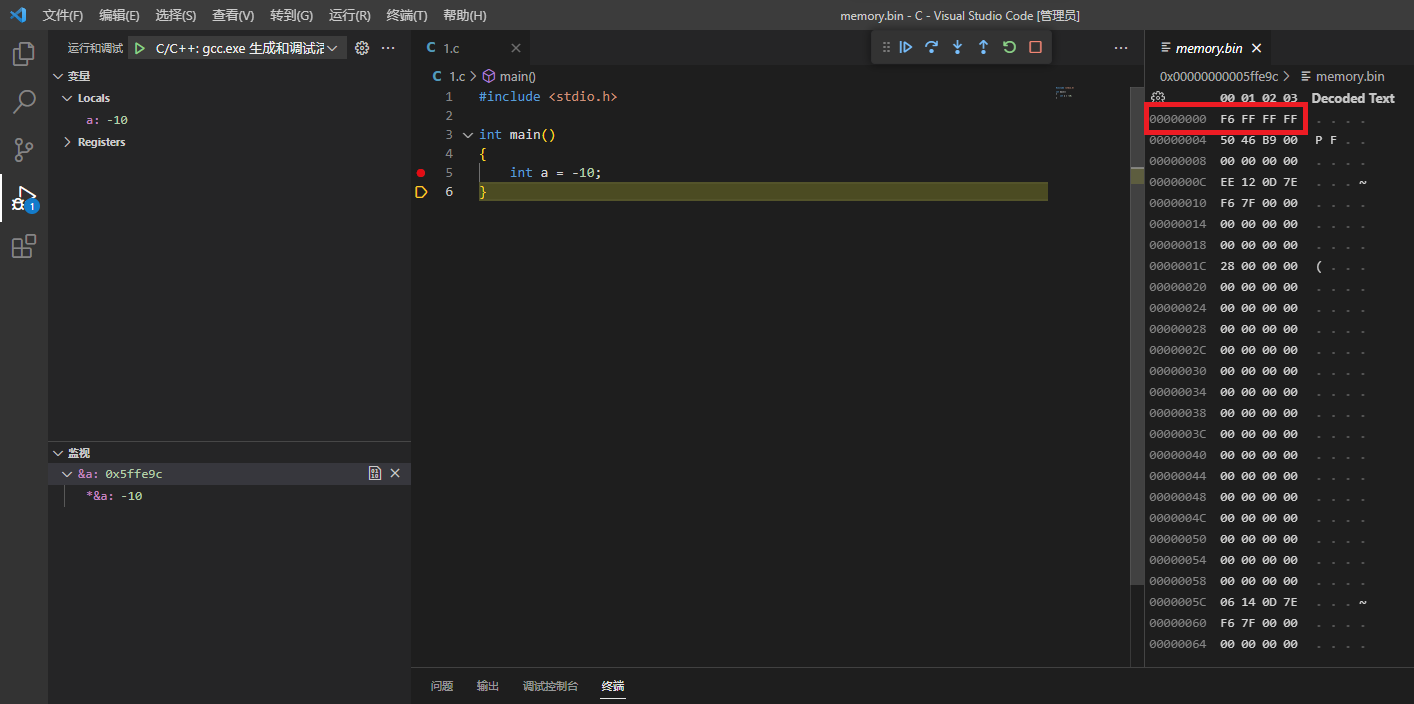
举例代码:
1 | |
VS Code 调试取 &a 的地址后可以观察发现 16 进制的内存地址所存储的数据为 F6 FF FF FF,这恰好是 2 进制补码的 16 进制数,同时表明了整数在内存中存储的是补码。
为什么数据在内存中存放的是补码:因为在计算机组成原理中,补码可以将符号位和数值域统一处理,加法和减法也可以统一处理(CPU只有加法器),此外补码和原码相互转换,运算过程是相同的,无需额外的逻辑硬件电路。
- 更深入的解释是原码虽然最直观,但存在一些局限性。一方面,负数的原码不能直接用于运算。例如在原码下计算 1 + (−2),得到的结果是 −3,这显然是不对的。为了解决此问题,计算机引入了反码。如果我们先将原码转换为反码,并在反码下计算 1 + (−2),最后将结果从反码转换回原码,则可得到正确结果 −1。
- 另一方面,数字零的原码有 +0 和 −0 两种表示方式。这意味着数字零对应两个不同的二进制编码,这可能会带来歧义。比如在条件判断中,如果没有区分正零和负零,则可能会导致判断结果出错。而如果我们想处理正零和负零歧义,则需要引入额外的判断操作,这可能会降低计算机的运算效率。
- 后面,计算机进一步引入了补码,在负零的反码基础上加 1 会产生进位,但 byte 类型的长度只有 8 位,因此溢出到第 9 位的 1 会被舍弃。也就是说,负零的补码为 0000 0000 ,与正零的补码相同。这意味着在补码表示中只存在一个零,正负零歧义从而得到解决。
举例代码:
1 | |
2.2 大端字节序和小端字节序
字节序(Byte Order)是指多字节数据在计算机内存中存储时的顺序。字节序分为两种主要类型:大端字节序(Big-Endian)和小端字节序(Little-Endian)。
大端字节序(Big-Endian):
- 在大端字节序中,多字节数据的最高有效字节(Most Significant Byte,MSB)存储在内存的最低地址处,而最低有效字节(Least Significant Byte,LSB)存储在内存的最高地址处。
- 大端字节序的表示方式类似于阅读书写的方式,先读取最高位的字节,然后是次高位,以此类推。
例如,十六进制数0x12345678在大端字节序中存储为:
1
0x12 0x34 0x56 0x78小端字节序(Little-Endian):
- 在小端字节序中,多字节数据的最低有效字节(LSB)存储在内存的最低地址处,而最高有效字节(MSB)存储在内存的最高地址处。
- 小端字节序的表示方式与计算机内部的数据存储方式相符,因此在许多计算机架构中使用较为广泛。
例如,十六进制数0x12345678在小端字节序中存储为:
1
0x78 0x56 0x34 0x12
字节序的选择在不同计算机架构和操作系统中可以有所不同。例如,x86 和 x86-64 架构通常使用小端字节序,而某些大型服务器架构(如SPARC)使用大端字节序。这种差异可能会在数据交换和网络通信中引起问题,因此在跨平台应用程序中,需要特别注意字节序的处理,以确保数据正确解释和传递。通常使用一种标准的字节序协议(如网络字节序)来协调不同架构之间的数据交换。
3. 总结
以上就是数据存储的基本原理,C 语言根据数据的类型在内存中开辟空间,操作系统根据内存地址来进行读取操作。整数在计算机中是以补码的形式存储的。在补码表示下,计算机可以对正数和负数的加法一视同仁,不需要为减法操作单独设计特殊的硬件电路,并且不存在正负零歧义的问题。如果深入,还有数据结构、内存管理、浮点数、字符编码等等方向可以探讨,从这里也可以窥探到计算机组成原理和它的体系实在是精妙。